1、进程和线程
1.1 什么是进程?>
进程就是CPU分配的最小单位,字面意思就是进行中的程序,我们可以理解为进程就是一个独立运行并且拥有自己的资源空间的任务程序;
CPU可以有很多进程,我们的电脑每打开一个软件就会产生一个或多个进程,为什么电脑运行的软件多就会卡,是因为CPU给每个进程分配资源空间,但是一个CPU一共就那么多资源,分出去越多,越卡,每个进程之间是相互独立的,CPU在运行一个进程时,其他的进程处于非运行状态,CPU使用 时间片轮转调度算法 来实现同时运行多个进程
1.2 什么是线程?>
线程是CPU调度的最小单位,线程是建立在进程基础上的一次程序运行单位,通俗讲线程就是程序中的一个执行任务,一个进程可以拥有多个线程。
一个进程中只有一个执行流称作单线程,即程序执行时,所走的程序路径按照连续顺序排下来,前面的必须处理好,后面的才会执行
一个进程中有多个执行流称作多线程,即在一个程序中可以同时运行多个不同的线程来执行不同的任务, 也就是说允许单个程序创建多个并行执行的线程来完成各自的任务
1.3 进程和线程的区别 >
进程是操作系统分配资源的最小单位,线程是程序执行的最小单位;
一个进程可以拥有多个线程,线程可以理解为是一个进程中代码的不同执行路线;
进程之间相互独立,一个进程之下的线程共享资源空间等;
1.4 多进程和多线程
多进程:多进程指的是在同一个时间里,同一个计算机系统中如果允许两个或两个以上的进程处于运行状态。多进程带来的好处是明显的,比如大家可以在网易云听歌的同时打开编辑器敲代码,编辑器和网易云的进程之间不会相互干扰
多线程:多线程是指程序中包含多个执行流,即在一个程序中可以同时运行多个不同的线程来执行不同的任务,也就是说允许单个程序创建多个并行执行的线程来完成各自的任务
1.5 JS为什么是单线程?
JS的单线程,与它的用途有关。作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。这决定了它只能是单线程,否则会带来很复杂的同步问题。比如,假定JavaScript同时有两个线程,一个线程在某个DOM节点上添加内容,另一个线程删除了这个节点,这时浏览器应该以哪个线程为准?
2、浏览器
2.1 浏览器是多进程的
我们每打开一个Tab页就会产生一个进程,我们使用Chrome打开很多标签页不关,电脑会越来越卡,不说其他,首先就很耗CPU
2.2 浏览器包含哪些进程? >>
· Browser进程
- 浏览器的主进程(负责协调、主控),该进程只有一个
- 负责浏览器界面显示,与用户交互。如前进,后退等
- 负责各个页面的管理,创建和销毁其他进程
- 将渲染(Renderer)进程得到的内存中的Bitmap(位图),绘制到用户界面上
- 网络资源的管理,下载等
· 第三方插件进程
- 每种类型的插件对应一个进程,当使用该插件时才创建
· GPU进程
- 该进程也只有一个,用于3D绘制等等
·** 渲染进程(重)**
- 即通常所说的浏览器内核(Renderer进程,内部是多线程)
- 每个Tab页面都有一个渲染进程,互不影响
- 主要作用为页面渲染,脚本执行,事件处理等
2.3 浏览器为什么要多进程?
我们假设浏览器是单进程,那么某个Tab页崩溃了,就影响了整个浏览器,体验有多差,同理如果插件崩溃了也会影响整个浏览器
2.4 简述渲染进程Renderer(重) >
页面的渲染,JS的执行,事件的循环,都在渲染进程内执行,所以我们要重点了解渲染进程
渲染进程是多线程的,我们来看渲染进程的一些常用较为主要的线程
2.4.1 GUI渲染线程 >
- **负责渲染浏览器界面,解析HTML,CSS,构建DOM树和RenderObject树,布局和绘制等 **
- 解析html代码(HTML代码本质是字符串)转化为浏览器认识的节点,生成DOM树,也就是DOM Tree
- 解析css,生成CSSOM(CSS规则树)
- 把DOM Tree 和CSSOM结合,生成Rendering Tree(渲染树)
- 当我们修改了一些元素的颜色或者背景色,页面就会重绘(Repaint)
- 当我们修改元素的尺寸,页面就会回流(Reflow)
- 当页面需要Repaing和Reflow时GUI线程执行,绘制页面
- 回流(Reflow)比重绘(Repaint)的成本要高,我们要尽量避免Reflow和Repaint
- **GUI渲染线程与JS引擎线程是互斥的 **
- 当JS引擎执行时GUI线程会被挂起(相当于被冻结了)
- GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行
2.4.2 JS引擎线程 >
- JS引擎线程就是JS内核,负责处理Javascript脚本程序(例如V8引擎)
- JS引擎线程负责解析Javascript脚本,运行代码
- JS引擎一直等待着任务队列中任务的到来,然后加以处理
- 浏览器同时只能有一个JS引擎线程在运行JS程序,所以js是单线程运行的
- 一个Tab页(renderer进程)中无论什么时候都只有一个JS线程在运行JS程序
- **GUI渲染线程与JS引擎线程是互斥的,js引擎线程会阻塞GUI渲染线程 **
- 就是我们常遇到的JS执行时间过长,造成页面的渲染不连贯,导致页面渲染加载阻塞(就是加载慢)
- 例如浏览器渲染的时候遇到
2.4.3 事件触发线程 >
- 属于浏览器而不是JS引擎,用来控制事件循环,并且管理着一个事件队列(task queue)
- 当js执行碰到事件绑定和一些异步操作(如setTimeOut,也可来自浏览器内核的其他线程,如鼠标点击、AJAX异步请求等),会走事件触发线程,将对应的事件添加到对应的线程中(比如定时器操作,便把定时器事件添加到定时器线程),等异步事件有了结果,便把他们的回调操作添加到事件队列,等待js引擎线程空闲时来处理。
- 当对应的事件符合触发条件被触发时,该线程会把事件添加到待处理队列的队尾,等待JS引擎的处理
- 因为JS是单线程,所以这些待处理队列中的事件都得排队等待JS引擎处理
2.4.4 定时触发器线程 >
- setInterval与setTimeout所在线程
- 浏览器定时计数器并不是由JavaScript引擎计数的(因为JavaScript引擎是单线程的,如果处于阻塞线程状态就会影响记计时的准确)
- 通过单独线程来计时并触发定时(计时完毕后,添加到事件触发线程的事件队列中,等待JS引擎空闲后执行),这个线程就是定时触发器线程,也叫定时器线程
- W3C在HTML标准中规定,规定要求setTimeout中低于4ms的时间间隔算为4ms
2.4.5 异步http请求线程 >
- 在XMLHttpRequest在连接后是通过浏览器新开一个线程请求
- 将检测到状态变更时,如果设置有回调函数,异步线程就产生状态变更事件,将这个回调再放入事件队列中再由JavaScript引擎执行
- 简单说就是当执行到一个http异步请求时,就把异步请求事件添加到异步请求线程,等收到响应(准确来说应该是http状态变化),再把回调函数添加到事件队列,等待js引擎线程来执行
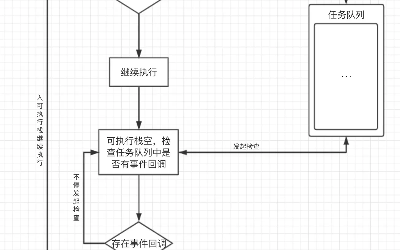
3 事件循环(Event Loop) >
首先要知道,JS分为同步任务和异步任务
同步任务都在主线程(这里的主线程就是JS引擎线程)上执行,会形成一个执行栈
主线程之外,事件触发线程管理着一个任务队列,只要异步任务有了运行结果,就在任务队列之中放一个事件回调
**一旦执行栈中的所有同步任务执行完毕(也就是JS引擎线程空闲了),**系统就会读取任务队列,将可运行的异步任务(任务队列中的事件回调,只要任务队列中有事件回调,就说明可以执行)添加到执行栈中,开始执行
let setTimeoutCallBack = function() {
console.log('我是定时器回调');
};
let httpCallback = function() {
console.log('我是http请求回调');
}
// 同步任务
console.log('我是同步任务1');
// 异步定时任务
setTimeout(setTimeoutCallBack,1000);
// 异步http请求任务
ajax.get('/info',httpCallback);
// 同步任务
console.log('我是同步任务2');
// setTimeout和Http请求为异步宏任务,回调入宏任务队列,回调的执行顺序也就是回调入队列的时间不一定谁先谁后,因为http请求时间不固定,settimeout的延迟时间也不固定,上面如果http请求在1s内请求结束,那就是http回调先入队列,超过1s就是settimeout先入上述代码执行过程
JS是按照顺序从上往下依次执行的,可以先理解为这段代码时的执行环境就是主线程,也就是也就是当前执行栈
首先,执行console.log(‘我是同步任务1’)
接着,执行到setTimeout时,会移交给定时器线程,通知定时器线程 1s 后将 setTimeoutCallBack 这个回调交给事件触发线程处理,在 1s 后事件触发线程会收到 setTimeoutCallBack 这个回调并把它加入到事件触发线程所管理的事件队列中等待执行
接着,执行http请求,会移交给异步http请求线程发送网络请求,请求成功后将 httpCallback 这个回调交由事件触发线程处理,事件触发线程收到 httpCallback 这个回调后把它加入到事件触发线程所管理的事件队列中等待执行
再接着执行console.log(‘我是同步任务2’)
至此主线程执行栈中执行完毕,JS引擎线程已经空闲,开始向事件触发线程发起询问,询问事件触发线程的事件队列中是否有需要执行的回调函数,如果有将事件队列中的回调事件加入执行栈中,开始执行回调,如果事件队列中没有回调,JS引擎线程会一直发起询问,直到有为止
到了这里我们发现,浏览器上的所有线程的工作都很单一且独立,非常符合单一原则
定时触发线程只管理定时器且只关注定时不关心结果,定时结束就把回调扔给事件触发线程
异步http请求线程只管理http请求同样不关心结果,请求结束把回调扔给事件触发线程
事件触发线程只关心异步回调入事件队列
而我们JS引擎线程只会执行执行栈中的事件,执行栈中的代码执行完毕,就会读取事件队列中的事件并添加到执行栈中继续执行,这样反反复复就是我们所谓的事件循环(Event Loop)

首先,执行栈开始顺序执行
判断是否为同步,异步则进入异步线程,最终事件回调给事件触发线程的任务队列等待执行,同步继续执行
执行栈空,询问任务队列中是否有事件回调
任务队列中有事件回调则把回调加入执行栈末尾继续从第一步开始执行
任务队列中没有事件回调则不停发起询问
4 宏任务和微任务 >
4.1 宏任务 >
我们可以将每次执行栈执行的代码当做是一个宏任务(包括每次从事件队列中获取一个事件回调并放到执行栈中执行), 每一个宏任务会从头到尾执行完毕,不会执行其他
由于JS引擎线程和GUI渲染线程是互斥的关系,浏览器为了能够使宏任务和DOM任务有序的进行,会在一个宏任务执行结果后,在下一个宏任务执行前,GUI渲染线程开始工作,对页面进行渲染
宏任务 -> GUI渲染 -> 宏任务 -> …
常见的宏任务
- 主代码块(同步任务)
- setTimeout
- setInterval
- setImmediate ()-Node
- requestAnimationFrame ()-浏览器
4.2 微任务 >
我们已经知道宏任务结束后,会执行渲染,然后执行下一个宏任务, 而微任务可以理解成在当前宏任务执行后立即执行的任务
当一个宏任务执行完,会在渲染前,将执行期间所产生的所有微任务都执行完
宏任务 -> 微任务 -> GUI渲染 -> 宏任务 -> …
常见微任务
- process.nextTick ()-Node
- Promise.then()
- catch
- finally
- Object.observe
- MutationObserver
4.3 简单区分 宏任务 和 微任务 >
document.body.style = 'background:black';
document.body.style = 'background:red';
document.body.style = 'background:blue';
document.body.style = 'background:pink';


我们看到上面动图背景直接渲染了粉红色,根据上文里讲浏览器会先执行完一个宏任务,再执行当前执行栈的所有微任务,然后移交GUI渲染,上面四行代码均属于同一次宏任务,全部执行完才会执行渲染,渲染时GUI线程会将所有UI改动优化合并,所以视觉上,只会看到页面变成粉红色
document.body.style = 'background:blue';
setTimeout(()=>{
document.body.style = 'background:black'
},200)



上述代码中,页面会先卡一下蓝色,再变成黑色背景,页面上写的是200毫秒,大家可以把它当成0毫秒,因为0毫秒的话由于浏览器渲染太快,录屏不好捕捉,我又没啥录屏慢放的工具,大家可以自行测试的,结果也是一样,最安全的方法是写一个index.html文件,在这个文件中插入上面的js脚本,然后浏览器打开,谷歌下使用控制台中performance功能查看一帧一帧的加载最为恰当,不过这样录屏不好录所以。。。
回归正题,之所以会卡一下蓝色,是因为以上代码属于两次宏任务,第一次宏任务执行的代码是将背景变成蓝色,然后触发渲染,将页面变成蓝色,再触发第二次宏任务将背景变成黑色
document.body.style = 'background:blue'
console.log(1);
Promise.resolve().then(()=>{
console.log(2);
document.body.style = 'background:pink'
});
console.log(3);

 控制台输出 1 3 2 , 是因为 promise 对象的 then 方法的回调函数是异步执行,所以 2 最后输出
控制台输出 1 3 2 , 是因为 promise 对象的 then 方法的回调函数是异步执行,所以 2 最后输出
页面的背景色直接变成粉色,没有经过蓝色的阶段,是因为,我们在宏任务中将背景设置为蓝色,但在进行渲染前执行了微任务, 在微任务中将背景变成了粉色,然后才执行的渲染
4.4 宏任务 微任务 注意点
- 浏览器会先执行一个宏任务,紧接着执行当前执行栈产生的微任务,再进行渲染,然后再执行下一个宏任务
- **微任务和宏任务不在一个任务队列,不在一个任务队列 **
- 例如setTimeout是一个宏任务,它的事件回调在宏任务队列,Promise.then()是一个微任务,它的事件回调在微任务队列,二者并不是一个任务队列
- 以Chrome 为例,有关渲染的都是在渲染进程中执行,渲染进程中的任务(DOM树构建,js解析…等等)需要主线程执行的任务都会在主线程中执行,而浏览器维护了一套事件循环机制,主线程上的任务都会放到消息队列中执行,主线程会循环消息队列,并从头部取出任务进行执行,如果执行过程中产生其他任务需要主线程执行的,渲染进程中的其他线程会把该任务塞入到消息队列的尾部,消息队列中的任务都是宏任务
- 微任务是如何产生的呢?当执行到script脚本的时候,js引擎会为全局创建一个执行上下文,在该执行上下文中维护了一个微任务队列,当遇到微任务,就会把微任务回调放在微队列中,当所有的js代码执行完毕,在退出全局上下文之前引擎会去检查该队列,有回调就执行,没有就退出执行上下文,这也就是为什么微任务要早于宏任务,也是大家常说的,每个宏任务都有一个微任务队列(由于定时器是浏览器的API,所以定时器是宏任务,在js中遇到定时器会也是放入到浏览器的队列中)
4.5 图解 宏任务 微任务 >

首先执行一个宏任务,执行结束后判断是否存在微任务
有微任务先执行所有的微任务,再渲染,没有微任务则直接渲染
然后再接着执行下一个宏任务
4.6 图解完整的Event Loop >

首先,整体的script(作为第一个宏任务)开始执行的时候,会把所有代码分为同步任务、异步任务两部分
同步任务会直接进入主线程依次执行
异步任务会再分为宏任务和微任务
宏任务进入到Event Table中,并在里面注册回调函数,每当指定的事件完成时,Event Table会将这个函数移到Event Queue中
微任务也会进入到另一个Event Table中,并在里面注册回调函数,每当指定的事件完成时,Event Table会将这个函数移到Event Queue中
当主线程内的任务执行完毕,主线程为空时,会检查微任务的Event Queue,如果有任务,就全部执行,如果没有就执行下一个宏任务
上述过程会不断重复,这就是Event Loop,比较完整的事件循环
5 关于Promise >
其实Promise是一个构造函数,自己的身上定义这all、race、reject、resolve这几个常用的方法,Promise的原型对象上有.then、catch、finally
new Promise(() => {}).then() ,我们来看这样一个Promise代码
前面的 new Promise() 这一部分是一个构造函数,这是一个同步任务
后面的 .then() 才是一个异步微任务,这一点是非常重要的
new Promise((resolve) => {
console.log(1)
resolve()
}).then(()=>{
console.log(2)
})
console.log(3)
// 上面代码输出1 3 2async/ await
一个函数如果加上 async ,那么该函数就会返回一个 Promise,async 就是将函数返回值使用 Promise.resolve() 包裹了下
async 和 await 可以说是异步终极解决方案了,相比直接使用 Promise 来说,**优势在于处理 then 的调用链,**能够更清晰准确的写出代码,毕竟写一大堆 then 也很恶心,并且也能优雅地解决回调地狱问题。当然也存在一些缺点,因为 await 将异步代码改造成了同步代码,如果多个异步代码没有依赖性却使用了 await 会导致性能上的降低。
5.1 实现Promise.all方法
function myPromiseAll(promises){
return new Promise(function(resolve,reject){
// 首先 all方法接收的参数 是一个数组 如果不是 则返回错误提示信息
if(!Array.isArray(promises)){
return new TypeError('argument must be a array')
}
// 计数
let resolvedCounter = 0
let promiseNum = promise.length
// 返回的数组
let resolvedResult = []
// 循环遍历传入的promise数组
for(let i = 0; i< promiseNum; i++){
// 为每个元素采用Promise.resolve包装一层,变成了Promise对象
Promise.resolve(promises[i]).then(value =>{
resolvedCounter++
resolvedResult[i] = value
// 表示数组执行完毕
if(resolvedCounter == promiseNum){
// 返回resolvedResult结果数组
return resolve(resolvedResult)
}
}, error => {
return reject(error)
})
}
})
}
// test
let p1 = new Promise(function(resolve, reject){
setTimeout(function (){
resolve(1)
},1000)
})
let p2 = new Promise(function(resolve, reject){
setTimeout(function (){
resolve(2)
},1000)
})
let p3 = new Promise(function(resolve, reject){
setTimeout(function (){
resolve(3)
},1000)
})
myPromiseAll([p3,p1,p2]).then(res => console.log(res)) // 3 1 25.2 实现Promise.race方法
Promise.race = function(args){
return new Promise((resolve,reject)=>{
for(let i = 0; i < args.length; i++){
args[i].then(resolve,reject)
}
})
}5.3 实现一个Promise
const PENDING = "pending"
const RESOLVE = "resolved"
const REJECTED = "rejected"
function MyPromise(fn){
// 保存初始化状态
let self = this
// 初始化状态
this.state = PENDING
// 用于保存resolve或者rejected传入的值
this.value = null
// 用于保存resolve的回调函数
this.resolveCallbacks = []
// 用于保存reject的回调函数
this.rejectCallbacks = []
// 状态转变为resolved方法
functionresolve(value){
// 判断传入的元素是否为Prmise值,如果是,则状态改变必须灯带前一个状态改变后再进行
if(value instanceof Promise){
return value.then(resolve,reject)
}
// 保证代码的执行顺序为本轮事件循环的末尾
setTimeout(()=>{
// 只有状态为pending时候才能改变
if(self.state === PENDING){
// 修改状态
self.state = RESOLVED
// 设置传入的值
self.value = value
// 执行回调函数
self.resolvedCallbacks.forEach(callback => {
callback(value)
})
}
},0)
}
// 状态变为rejected方法
function reject(value){
// 保证代码的执行顺序为本轮事件循环的末尾
setTimeout(()=>{
// 只有状态为pending的时候才能转变
if(self.state === PENDING){
// 修改状态
self.state = REJECTED
// 设置传入的值
self.value = value
// 执行回调函数
self.rejectedCallbacks.forEach(callback => {
callback(value)
})
}
},0)
}
// 将两个方法传入函数执行
try{
fn(resolve,reject)
}catch(e){
// 遇到错误的时候,捕获错误,执行reject函数
reject(e)
}
}
MyPromise.prototype.then = function(onResolved,onRejected){
// 首先判断两个参数是为函数类型,因为这两个参数是可选参数
onResolved = typeof onResolved === "function" ? onResolved :function(value){
return value
}
onRejected = typeof onRejected === "function" ? onRejected : function(error){
throw error
}
// 如果是灯带状态,则将函数加入对应列表中
if(this.state === PENDING){
this.resolvedCallbacks.push(onResolved)
this.rejectedCallbacks.push(onRejected)
}
// 如果状态已经凝固,则直接执行对应状态的函数
if(this.state === RESOLVED){
onRejected(this.value)
}
}6 关于async await >
async/await本质上还是基于Promise的一些封装,而Promise是属于微任务的一种
所以在使用await关键字与Promise.then效果类似
setTimeout(() => console.log(4))
async function test() {
console.log(1)
await Promise.resolve()
console.log(3)
}
test()
console.log(2)
上述代码输出1 2 3 4
可以理解为,await 以前的代码,相当于与 new Promise 的同步代码,await 以后的代码相当于 Promise.then的异步
function test() {
console.log(1)
// 异步宏任务
setTimeout(function () { // timer1
console.log(2)
}, 1000)
}
test();
// 异步宏任务
setTimeout(function () { // timer2
console.log(3)
})
new Promise(function (resolve) {
console.log(4)
// 异步宏任务
setTimeout(function () { // timer3
console.log(5)
}, 100)
resolve()
// 异步微任务
}).then(function () {
// 异步宏任务
setTimeout(function () { // timer4
console.log(6)
}, 0)
// 同步
console.log(7)
})
console.log(8)
1 4 8 7 3 6 5 2结合我们上述的JS运行机制再来看这道题就简单明了的多了
JS是顺序从上而下执行
执行到test(),test方法为同步,直接执行,console.log(1)打印1
test方法中setTimeout为异步宏任务,回调我们把它记做timer1放入宏任务队列
接着执行,test方法下面有一个setTimeout为异步宏任务,回调我们把它记做timer2放入宏任务队列
接着执行promise,new Promise是同步任务,直接执行,打印4
new Promise里面的setTimeout是异步宏任务,回调我们记做timer3放到宏任务队列
Promise.then是微任务,放到微任务队列
console.log(8)是同步任务,直接执行,打印8
主线程任务执行完毕,检查微任务队列中有Promise.then
开始执行微任务,发现有setTimeout是异步宏任务,记做timer4放到宏任务队列
微任务队列中的console.log(7)是同步任务,直接执行,打印7
微任务执行完毕,第一次循环结束
检查宏任务队列,里面有timer1、timer2、timer3、timer4,四个定时器宏任务,按照定时器延迟时间得到可以执行的顺序,即Event Queue:timer2、timer4、timer3、timer1,依次拿出放入执行栈末尾执行 (插播一条:浏览器 event loop 的 Macrotask queue,就是宏任务队列在每次循环中只会读取一个任务)
执行timer2,console.log(3)为同步任务,直接执行,打印3
检查没有微任务,第二次Event Loop结束
执行timer4,console.log(6)为同步任务,直接执行,打印6
检查没有微任务,第三次Event Loop结束
执行timer3,console.log(5)同步任务,直接执行,打印5
检查没有微任务,第四次Event Loop结束
执行timer1,console.log(2)同步任务,直接执行,打印2
检查没有微任务,也没有宏任务,第五次Event Loop结束
结果:1,4,8,7,3,6,5,2
7、webpack相关
7.1 有哪些常见的Loader?你用过哪些Loader?
- sass-loader 将SCSS/SASS代码转化成CSS
- less-loader 将LESS代码转化成CSS
- css-loader 加载CSS,支持模块化、压缩、文件导入等特性
- style-loader 将CSS代码注入到JS中
- babel-loader 将ES6转化为ES7
- ts-loader 将TS转化为JS
- image-loader 加载并压缩图片文件
- file-loader 把文件输出到一个文件夹中,在代码中通过相对URL去饮用输出到文件(处理图片和字体)
- url-loader 和file-loader的区别在于 用户可以设置一个阀值,超过阀值会交给file-loader处理,小于阀值会返回base64形式编码
7.2 有哪些常见的plugin?你用过哪些plugin?
- ignore-plugin 忽略部分文件
- html-webpack-plugin:当使用 webpack打包时,创建一个 html 文件,并把 webpack 打包后的静态文件自动插入到这个 html 文件当中。
const HtmlWebpackPlugin = require('html-webpack-plugin')
module.exports = {
entry: 'index.js',
output: {
path: __dirname + '/dist',
filename: 'index_bundle.js'
},
plugins: [
new HtmlWebpackPlugin()
]
}
// html-webpack-plugin 默认将会在 output.path 的目录下创建一个 index.html 文件, 并在这个文件中插入一个 script 标签,标签的 src 为 output.filename。 用来产出一个html文件,往里面自动插入生成的脚本- mini-css-extract-plugin: 分离样式文件,css提取为独立文件
- webpack-merge:用于提取公共配置,减少重复配置代码
- HotModuleReplacementPlugin:热更新
7.3 Loader和Plugin的区别
Loader本质上是个函数,在该函数中对接收到的内容进行转换,返回转换后的结果。因为webpack只认识JS,所以Loader就成了翻译官,对其它类型的资源进行转译的预处理。
Plugin就是插件,用于扩展webpack的功能,基于事件流框架 Tapable,插件可以扩展 Webpack 的功能,在 Webpack 运行的生命周期中会广播出许多事件,Plugin 可以监听这些事件,在合适的时机通过 Webpack 提供的 API 改变输出结果。
7.4 webpack 构建流程
webpack 构建的核心任务是完成内容转化和资源合并。主要包含以下 3 个阶段:
- 初始化阶段
- 初始化参数:从配置文件、配置对象和 Shell 参数中读取并与默认参数进行合并,组合成最终使用的参数。
- 创建编译对象:用上一步得到的参数创建 Compiler 对象。
- 初始化编译环境:包括注入内置插件、注册各种模块工厂、初始化 RuleSet 集合、加载配置的插件等。
- 构建阶段
- 开始编译:执行 Compiler 对象的 run 方法,创建 Compilation 对象。
- 确认编译入口:进入 entryOption 阶段,读取配置的 Entries,递归遍历所有的入口文件,调用 Compilation.addEntry 将入口文件转换为 Dependency 对象。
- 编译模块(make): 调用 normalModule 中的 build 开启构建,从 entry 文件开始,调用 loader 对模块进行转译处理,然后调用 JS 解释器(acorn)将内容转化为 AST 对象,然后递归分析依赖,依次处理全部文件。
- 完成模块编译:在上一步处理好所有模块后,得到模块编译产物和依赖关系图。
- 生成阶段
- 输出资源(seal):根据入口和模块之间的依赖关系,组装成多个包含多个模块的 Chunk,再把每个 Chunk 转换成一个 Asset 加入到输出列表,这步是可以修改输出内容的最后机会。
- 写入文件系统(emitAssets):确定好输出内容后,根据配置的 output 将内容写入文件系统。
webpack 构建的核心任务是完成内容转化和资源合并。主要包含以下 5 个阶段:
- 初始化参数:解析webpack配置参数,合并shell传入和webpack.config.js文件配置的参数,形成最后的配置;
- 开始编译:上一步得到的参数初始化compiler对象,注册所有配置的插件,插件监听webpack构建生命周期的事件节点,做出相应的反应,执行对象的run方法开始执行编译;
- 确定入口:从配置的 entry出口,开始解析文件构建AST语法树,找出依赖,递归下去;
- 编译模块:递归中根据文件类型和loader配置,调用所有配置的loader对文件进行转换,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过本步骤的处理;
- 完成模块编译并输出:递归完成后,得到的每个问津结果,包含每个模块以及他们之间的依赖关系,根据entry或分包配置生成代码卡chunk;
- 输出完成:输出所有的chunk到文件系统;
compiler 对象代表的是构建过程中不变的webpack 环境,整个webpack 从启动到关闭的生命周期。 针对的是webpack。
compilation 对象只代表一次新的编译,只要项目文件有改动,compilation 就会被重新创建。** 针对的是随时可变的项目文件。**
构建流程:简单说 就分为三个阶段, 初始化阶段,构建阶段,输出阶段,(也可以说成五步),主要做了这几件事,就是初始化阶段:解析读取与合并webpack配置参数,加载 Plugin,实例化 Compiler;构建阶段:从入口文件entry出发,解析文件构建AST语法树,找出依赖,递归下去,最后就是根据entry和module之间的依赖关系,组装成chunk,然后转化为文件输出到文件系统;
7.5 source map是什么? 生产环境怎么用?
source map 是将编译、打包、压缩后的代码映射回源代码的过程。打包压缩后的代码不具备良好的可读性,想要调试源码就需要 soucre map。
线上环境一般有三种处理方案:
- hidden-source-map:借助第三方错误监控平台 Sentry 使用
- nosources-source-map:只会显示具体行数以及查看源代码的错误栈。安全性比 sourcemap 高
- sourcemap:通过 nginx 设置将 .map 文件只对白名单开放(公司内网)
注意:避免在生产中使用 inline- 和 eval-,因为它们会增加 bundle 体积大小,并降低整体性能。
生产环境不推荐使用source map
7.6 模块打包原理 >
Webpack 实际上为每个模块创造了一个可以导出和导入的环境,本质上并没有修改 代码的执行逻辑,代码执行顺序与模块加载顺序也完全一致。
7.7 文件监听原理
轮询判断文件的最后编辑时间是否变化,如果某个文件发生了变化,并不会立刻告诉监听者,而是先缓存起来,等 aggregateTimeout 后再执行。
在发现源码发生变化时,自动重新构建出新的输出文件。
Webpack开启监听模式,有两种方式:
- 启动 webpack 命令时,带上 —watch 参数
- 在配置 webpack.config.js 中设置 watch:true
缺点:每次需要手动刷新浏览器
module.export = {
// 默认false,也就是不开启
watch: true,
// 只有开启监听模式时,watchOptions才有意义
watchOptions: {
// 默认为空,不监听的文件或者文件夹,支持正则匹配
ignored: /node_modules/,
// 监听到变化发生后会等300ms再去执行,默认300ms
aggregateTimeout:300,
// 判断文件是否发生变化是通过不停询问系统指定文件有没有变化实现的,默认每秒问1000次
poll:1000 }
}7.8 热更新(HMR)原理 >
热更新可以做到不用刷新浏览器而将新变更的模块替换掉旧的模块。
**热更新(HMR)**的核心就是客户端从服务端拉去更新后的文件,准确的说是 chunk diff (chunk 需要更新的部分),实际上 Webpack-Dev-Server 与浏览器之间维护了一个 Websocket,当本地资源发生变化时, Webpack-Dev-Server 会向浏览器推送更新,并带上构建时的 hash,与之前存在差异,客户端会向 Webpack-Dev-Server 发起 Ajax 请求来获取更改内容(文件列表、hash),这样客户端就可以再借助这些信息继续向 Webpack-Dev-Server 发起 jsonp 请求获取该chunk的增量更新。
7.9 如何对bundle体积进行监控分析?
使用 webpack-bundle-analyzer 生成 bundle 的模块组成图,显示所占体积。
7.10 如何控制loader作用顺序?>
可以使用 enforce 强制执行 loader 的作用顺序,pre 代表在所有正常 loader 之前执行,post 是所有 loader 之后执行。
7.11 如何优化Webpack构建速度?(重)>
- 多进程/多实例构建:HappyPack(不维护了)、thread-loader
- 压缩代码
- 多进程并行压缩
- webpack-paralle-uglify-plugin
- uglifyjs-webpack-plugin 开启 parallel 参数 (不支持ES6)
- terser-webpack-plugin 开启 parallel 参数
- 通过 mini-css-extract-plugin 提取 Chunk 中的 CSS 代码到单独文件,通过 css-loader 的 minimize 选项开启 cssnano 压缩 CSS。
- 多进程并行压缩
- 图片压缩
- 使用基于 Node 库的 imagemin (很多定制选项、可以处理多种图片格式)
- 配置 image-webpack-loader
- 缩小打包作用域:
- exclude/include (确定 loader 规则范围)
- resolve.modules 指明第三方模块的绝对路径 (减少不必要的查找)
- resolve.mainFields 只采用 main 字段作为入口文件描述字段 (减少搜索步骤,需要考虑到所有运行时依赖的第三方模块的入口文件描述字段)
- resolve.extensions 尽可能减少后缀尝试的可能性
- noParse 对完全不需要解析的库进行忽略 (不去解析但仍会打包到 bundle 中,注意被忽略掉的文件里不应该包含 import、require、define 等模块化语句)
- IgnorePlugin (完全排除模块)
- 合理使用alias
- 提取页面公共资源:
- 基础包分离:
- 使用 html-webpack-externals-plugin,将基础包通过 CDN 引入,不打入 bundle 中
- 使用 SplitChunksPlugin 进行(公共脚本、基础包、页面公共文件)分离(Webpack4内置) ,替代了 CommonsChunkPlugin 插件
- 基础包分离:
- DLL:
- 使用 DllPlugin 进行分包,使用 DllReferencePlugin(索引链接) 对 manifest.json 引用,让一些基本不会改动的代码先打包成静态资源,避免反复编译浪费时间。
- HashedModuleIdsPlugin 可以解决模块数字id问题
- 充分利用缓存提升二次构建速度:
- babel-loader 开启缓存
- terser-webpack-plugin 开启缓存
- 使用 cache-loader 或者 hard-source-webpack-plugin
- Tree shaking
- 打包过程中检测工程中没有引用过的模块并进行标记,在资源压缩时将它们从最终的bundle中去掉(只能对ES6 Modlue生效) 开发中尽可能使用ES6 Module的模块,提高tree shaking效率
- 禁用 babel-loader 的模块依赖解析,否则 Webpack 接收到的就都是转换过的 CommonJS 形式的模块,无法进行 tree-shaking
- 使用 PurifyCSS(不在维护) 或者 uncss 去除无用 CSS 代码
- purgecss-webpack-plugin 和 mini-css-extract-plugin配合使用(建议)
- Scope hoisting
- 构建后的代码会存在大量闭包,造成体积增大,运行代码时创建的函数作用域变多,内存开销变大。Scope hoisting 将所有模块的代码按照引用顺序放在一个函数作用域里,然后适当的重命名一些变量以防止变量名冲突
- 必须是ES6的语法,因为有很多第三方库仍采用 CommonJS 语法,为了充分发挥 Scope hoisting 的作用,需要配置 mainFields 对第三方模块优先采用 jsnext:main 中指向的ES6模块化语法
- 动态Polyfill
- 建议采用 polyfill-service 只给用户返回需要的polyfill,社区维护。 (部分国内奇葩浏览器UA可能无法识别,但可以降级返回所需全部polyfill)
7.12 有没有做过webpack优化构建速度? (重) >
7.12.1前言
开发CDE项目的时候,每次打包构建项目的时间都比较久,如下图所示,开发环境下需要一分钟的时间才能构建完成,
同时开发环境下实时打包编译的时间也比较久,如下图所示,接近10s。阅读过该项目webpack.config.js的配置后,感觉有优化的空间,为了提升开发效率,遂对webpack的相关配置进行重构。
7.12.2 优化一:合并提取webpack公共配置
webpack配置分为开发环境配置和生产环境配置,在两种环境的配置文件中,存在大量的重复配置,也有部分不同的配置,如在开发阶段,我们为了提升运行效率以及调试效率, 一般会通过dev-server来实时打包,这样就无需每次在终端输入脚本命令打包,而在上线阶段我们需要拿到真实的打包文件, 所以不会通过dev-server来打包。为了提升打包效率,开发阶段不会对打包的内容进行压缩;而在上线阶段,为了提升访问的效率,在打包时需要对打包的内容进行压缩。
旧配置文件的问题及相应的改进
旧配置文件将开发环境和线上环境的配置都写到了一个文件中, 这样非常不利于我们去维护配置文件,所以我们需要针对不同的环境将不同的配置写到不同的文件中, 我们可以在根路径下创建如下目录结构,将两种环境下共有的配置抽取到webpack.common.js文件中,webpack.dev.js文件和webpack.prod.js文件分别存放开发环境和生产环境下特有的配置。
开发环境与生产环境各自的特有配置与共有配置的合并,具体需要用到webpack-merge模块来处理。
关键代码示例
webpack.dev.js
const { merge } = require("webpack-merge");
const CommonConfig = require("./webpack.common.js");
module.exports = merge(CommonConfig, DevConfig);webpack.prod.js
const { merge } = require("webpack-merge");
const CommonConfig = require("./webpack.common.js");
module.exports = merge(CommonConfig, ProdConfig);package.json
"scripts": {
"dev": "webpack-dev-server --config webpack-config/webpack.dev.js",
"build": "webpack --config webpack-config/webpack.prod.js"
}7.12.3 优化二:HappyPack实现多进程打包(开发环境和生产环境均适用)
运行在Node.js之上的Webpack是单线程模型的,也就是说Webpack需要一个一个地处理任务,不能同时处理多个任务。而HappyPack可以让Webpack 在同一时刻处理多个任务,发挥多核CPU电脑的功能,提升构建速度。它将任务分解给多个子进程去并发执行,子进程处理完后再将结果发送给主进程。由于 JavaScript 是单线程模型,所以要想发挥多核 CPU 的功能,就只能通过多进程实现,而无法通过多线程实现。
在实际使用时,要用HappyPack提供的loader来替换原有loader,并将原有的那个通过HappyPack插件传进去。
下面我们使用HappyPack对旧配置文件进行改造:
初始Webpack配置(使用HappyPack前)
module.exports = {
//...
module: {
rules: [
{
test: /\.ts(x)?$/,
include: [path.resolve(__dirname, 'src')],
use: ['babel-loader', 'ts-loader'],
},
],
},
}
webpack.common.js (使用HappyPack的配置)
const HappyPack = require('happypack');
module.exports = {
//...
module: {
rules: [
{
test: /\.ts(x)?$/,
include: [path.resolve(__dirname, '../src')],
// 把对 .ts(x) 文件的处理转交给 id 为 ts 的 HappyPack 实例
use: ['happypack/loader?id=ts']
},
],
},
plugins: [
new HappyPack({
// 用唯一的标识符 id 来代表当前的 HappyPack 是用来处理一类特定的文件
id: 'ts',
// loaders属性表示如何处理 .ts(x) 文件,用法和 Loader 配置中一样
loaders: ['babel-loader','ts-loader']
],
};在loader的配置中,将对文件的处理交给happypack/loader,并且跟着的queryString ( id=ts )告诉happypack-loader去选择哪个happypack实例处理文件;
在plugin的配置中,新增happypack实例告诉happypack/loader如何去处理ts(x)文件,选项中的id属性值和上面的queryString(id=babel)是对应的,选项中loaders的属性和没有使用happypack前的loader的配置保持一致;
改进效果:
经过happyPack的处理后,开发环境下的构建时间由60多秒降至20多秒,打包构建所花的时间是之前的一半不到,提升打包性能的效果显著。
关于开启多进程的注意点:
开启多进程不是一定能够提高构建速度的,开启的子进程也不是越多越好,因为进程要启动,要销毁,进程之间要通讯,这个进程的开销也是比较大的。对于较大的项目,打包较慢,开启多进程能提高速度;对于较小的项目,打包很快,开启多进程会降低速度。
HappyPack的threads参数用于配置开启子进程的个数,默认是3个,笔者配置开启4个子进程的时候,构建速度和3个子进程的时候几乎没有差异,开启5个子进程的时候,构建速度比3个和4个的时候更慢。所以是否开启多进程,开启多少个进程,我们应当按需使用。
7.12.4 优化三:样式文件抽离和压缩(生产环境适用)
对于样式文件的处理,loader链中如果最后使用style-loader来处理,我们的css是直接打包进js里面的。生产环境下,我们希望能单独生成css文件。**因为单独生成css,css可以和js并行下载,提高页面加载效率。**同时,生产环境下也需要对css文件进行压缩处理,以减小文件体积,提高页面加载效率。而开发环境下,因为对文件的抽离和压缩比较耗时,为了提高打包构建的速度,以尽快开发,开发环境下,我们对样式文件不抽离不压缩。
旧配置文件的问题及相应的改进
原配置文件中,不论是开发环境还是生产环境scss文件最后一步都是通过style-loader进行处理,这是不合理的,那么下面我们对生产环境下的scss文件的处理进行改进,我们使用mini-css-extract-plugin抽离样式文件,使用
css-minimizer-webpack-plugin压缩样式文件,由于css-minimizer-webpack-plugin需要配置webpack的optimization.minimizer,这样会覆盖默认的JS压缩选项, 导致生产环境下的JS代码不被压缩了,所以JS代码也需要通过插件terser-webpack-plugin自己压缩**;**
代码示例如下:
webpack.prod.js
const MiniCssExtractPlugin = require('mini-css-extract-plugin');
const TerserJSPlugin = require('terser-webpack-plugin')
const CssMinimizerPlugin = require("css-minimizer-webpack-plugin")
module.exports = {
//...
module: {
rules: [
{
test: /\.(sass|scss)$/,
use:[
// 使用MiniCssExtractPlugin.loader代替style-loader,抽离css文件
MiniCssExtractPlugin.loader,
'css-loader',
'sass-loader', {
loader: 'sass-resources-loader',
options: {
resources: path.join(
srcPath,
'styles/_variables.scss',
),
},
}]
}
],
},
plugins: [
// 抽离 css 文件
new MiniCssExtractPlugin({
filename:'css/main.[contenthash:8].css'
}),
],
optimization: {
// 压缩 css
//因为覆盖了原本的配置,所以只压缩css的话,js就不被压缩了,所以需要让js也压缩;
minimizer: [new TerserJSPlugin(), new CssMinimizerPlugin()],
}
} 7.12.5 优化四:Dll动态链接库(开发环境适用)
在开发环境下,每次打包构建项目的时候,react,react-dom,antd等这些不会发生变化的第三方库都会被重新打包一次,而Dll动态链接库通过提前把这些不会发生变化的第三方模块打包到dll文件中,等到在开发环境下打包构建的时候,直接去dll文件中获取,不再打包这些模块,这样第三方模块只打包了一次,避免了反复打包不会发生变化的第三方模块,提升了webpack的打包效率。
注意,dllPlugin只适用于开发环境,因为生产环境下打包一次就完了,没有必要用于生产环境。
dll动态链接库使用步骤:
1.单独配置一个webpack.dll.js文件, 专门用于打包不会变化的第三方库
webpack.dll.js
module.exports = {
mode: 'production',
// JS 执行入口文件
entry: {
// 把 React, antd相关模块的放到一个单独的动态链接库
vendor: ['react', 'react-dom','antd','react-router-dom'],
},
output: {
// 输出的动态链接库的文件名称,[name] 代表当前动态链接库的名称,
// 也就是 entry 中配置的 vendor
filename: '[name].dll.js',
// 输出的文件都放到 dll 目录下
path: path.join(__dirname, '..', 'dll'),
// library表示打包的是一个库,存放动态链接库的全局变量名称,
// 例如对应 vendor 来说就是 _dll_vendor
// 之所以在前面加上 _dll_ 是为了防止全局变量冲突
library: '_dll_[name]',
}
}2.在打包项目的配置文件中, 通过add-asset-html-webpack-plugin将提前打包好的库插入到html中
webpack.dev.js
const AddAssetHtmlWebpackPlugin = require('add-asset-html-webpack-plugin')
module.exports = {
//..
plugins: [
new AddAssetHtmlWebpackPlugin({
filepath:path.join(__dirname, '..', 'dll/vendor.dll.js'),
})
}3.在专门打包第三方的配置文件中添加生成清单文件manifest.json的配置(manifest.json文件清楚地描述了与其对应的vendor.dll.js文件中包含哪些模块,以及每个模块的路径和ID,是一个索引文件)
webpack.dll.js
const DllPlugin = require('webpack/lib/DllPlugin')
module.exports = {
//..
plugins: [
// 接入 DllPlugin
new DllPlugin({
// 动态链接库的全局变量名称,需要和 output.library 中保持一致
// 该字段的值也就是输出的 manifest.json 文件 中 name 字段的值
// 例如 vendor.manifest.json 中就有 "name": "_dll_vendor"
name: '_dll_[name]',
// 描述动态链接库的 manifest.json 文件输出时的文件名称
path: path.join(__dirname, '..', 'dll/[name].manifest.json'),
}),
]
}4.在打包项目的配置文件中, 告诉webpack打包第三方库的时候先从哪个清单文件中查询,如果清单包含当前用到的第三方库就不打包了,因为已经在html中手动引入了
webpack.dev.js
const DllReferencePlugin = require('webpack/lib/DllReferencePlugin');
module.exports = {
//..
new DllReferencePlugin({
manifest: require(path.join(__dirname, '..', 'dll/vendor.manifest.json'))
}),
}运行yarn dll后会生成一个dll目录,里面有两个文件vendor.dll.js和vendor.manifest.json,前者包含了库的代码,后者则是资源清单。
6.开发环境下执行构建项目
运行yarn dev
改进效果:
经过动态链接库dll的配置后,笔者发现项目构建的时间又减少了约2秒,一定程度上提高了构建效率。
7.12.6 优化五:babel-loader开启缓存提高二次构建速度(开发环境适用)
babel-loader 可以利用指定文件夹缓存经过 babel 处理好的模块,这样第二次编译的时候,对没有改动的部分直接用缓存,不会再次编译。
webpack.dev.js
module.exports = {
//...
module: {
rules: [
{
test: /\.ts(x)?$/,
include: [path.resolve(__dirname, 'src')],
// 当有设置cacheDirectory时,指定的目录将用来缓存 loader 的执行结果。
// 如下配置,loader 将使用默认的缓存目录 node_modules/.cache/babel-loader
use: ['babel-loader?cacheDirectory', 'ts-loader'],
},
],
},
}7.12.7 优化六:选择合适的Source Map
当 webpack 打包源代码时,可能会很难追踪到错误和警告在源代码中的原始位置, Source Map可以将编译后的代码映射回原始源代码。Source Map 本质上是一个信息文件,里面储存着代码转换前后的对应位置信息。它记录了转换压缩后的代码所对应的转换前的源代码位置,是源代码和生产代码的映射。 Source Map 解决了在打包过程中,代码经过压缩,去空格以及 babel 编译转化后,由于代码之间差异性过大,造成无法debug的问题。
Source Map的配置:
JavaScript的Source Map的配置很简单,只要在webpack配置中添加devtool即可。
对于css、scss、less来说,则需要添加额外的Source Map配置项。如下面例子所示:
module.exports = {
// ...
devtool: 'source-map',
module: {
rules: [
{
test: /\.scss$/,
use: [
'style-loader',
{
loader: 'css-loader',
options: {
sourceMap: true,
},
},
{
loader: 'sass-loader',
options: {
sourceMap: true,
},
}
] ,
}
],
},
};JavaScript的Source Map配置的选择:
Webpack支持多种Source Map的形式。除了配置为devtool:‘source-map’以外,还可以根据不同的需求选择cheap-source-map、eval-source-map等。通常它们都是source map的一些简略版本,因为生成完整的source map会延长整体构建时间,如果对打包速度需求比较高的话,建议选择一个简化版的source map。比如,在开发环境中,eval-cheap-module-source-map通常是一个不错的选择,属于打包速度和源码信息还原程度的一个良好折中。
下面介绍下Source Map配置的常见的各个组成部分的含义:
(1) eval:
不会单独生成Source Map文件, 会将映射关系存储到打包的文件中, 并且通过eval存储
(2) source-map:
会单独生成Source Map文件, 通过单独文件来存储映射关系
(3) inline:
不会单独生成Source Map文件, 会将映射关系存储到打包的文件中, 并且通过base64字符串形式存储
(4) cheap:
生成的映射信息只能定位到错误行不能定位到错误列
(5) module:
不仅希望存储我们代码的映射关系, 还希望存储第三方模块映射关系, 以便于第三方模块出错时也能更好的排错
eval-cheap-module-source-map只需要行错误信息, 并且包含第三方模块错误信息, 并且不会生成单独Source Map文件。在开发环境下不会做代码压缩,所以在Source Map中即使没有列信息,也不会影响断点调试。因为生成这种 Source Map 的速度也较快。所以在开发环境下我们将devtool设置成cheap-module-eval-source-map。
改进效果:
项目原配置文件开发环境下的Source Map选择的是’inline-source-map’, 经笔者实践,开发环境下,使用’inline-source-map’,修改某一处代码,实时编译的速度在3秒以上,改为使用’eval-cheap-module-source-map’,对代码做同样的修改,实时编译的速度在1-2秒,速度有明显的提升。
7.13 代码分割的本质是什么? 有什么意义呢?
代码分割的本质其实就是在源代码直接上线和打包成唯一脚本main.bundle.js这两种极端方案之间的一种更适合实际场景的中间状态。
「用可接受的服务器性能压力增加来换取更好的用户体验。」
源代码直接上线:虽然过程可控,但是http请求多,性能开销大。
打包成唯一脚本:一把梭完自己爽,服务器压力小,但是页面空白期长,用户体验不好。
7.14 是否写过Loader? 简单描述一下编写过程。
7.15 webpack Proxy的工作原理是什么?为什么能解决跨域?
webpack proxy 即 webpack提供的代理服务
基本行为就是接收客户端发送的请求后转发给其他服务器
**工作原理 **
proxy工作原理实质上是利用http-proxy-middleware 这个http代理中间件,实现请求转发给其他服务器
跨域 在开发阶段, webpack-dev-server 会启动一个本地开发服务器,所以我们的应用在开发阶段是独立运行在 localhost的一个端口上,而后端服务又是运行在另外一个地址上
所以在开发阶段中,由于浏览器同源策略的原因,当本地访问后端就会出现跨域请求的问题
通过设置webpack proxy实现代理请求后,相当于浏览器与服务端中添加一个代理者
当本地发送请求的时候,代理服务器响应该请求,并将请求转发到目标服务器,目标服务器响应数据后再将数据返回给代理服务器,最终再由代理服务器将数据响应给本地在代理服务器传递数据给本地浏览器的过程中,两者同源,并不存在跨域行为,这时候浏览器就能正常接收数据
注意:「服务器与服务器之间请求数据并不会存在跨域行为,跨域行为是浏览器安全策略限制」
8 redux和mobx的区别
8.1 什么是mobx?
MobX 是一个身经百战的库,它通过运用透明的函数式响应编程使状态管理变得简单和可扩展。
Mobx是一个通过函数响应式编程,让状态管理更加简单和容易拓展的库。 MobX背后的哲学很简单:**任何源自应用状态的东西都应该自动地获得。**简单来说就是状态只要一变,其他用到状态的地方就都跟着自动变。

Mobx 使用的是单向数据流,通过触发 action 去更新可响应的对象,继而去更新计算属性并触发副作用。
什么是可观察?就是 MobX 老大哥在看着 state 呢。state 只要一改变,所有用到它的地方就都跟着改变了。这样整个 View 可以被 state 来驱动。
- Actions 是唯一允许修改state而且有其他副作用的函数
- State 是一组可观察的状态,而且不应该包含冗余的数据(例如不会被更新的状态)
- Computed Value 是一些纯函数,返回通过 state 可以推导出的值
- Reactions 类似于 Computed Value,但是它允许副作用的产生(如更新 UI 状态)
https://juejin.cn/post/6850418118968377357
8.1.1 mobx的使用
Mobx通过 makeObservable/makeAutoObservable 方法来构造响应式对象,对象中的属性会通过 Proxy 代理,这和 Vue 相似。
makeObservable/makeAutoObservable:区别
**makeAutoObservable 就像加强版的makeObservable,**在默认情况下它将推断所有的属性是可观察的(observable),新成员不再需要显示的提及。makeAutoObservable 不能被用于带有 super 的类或 子类。
在 makeObservable 函数中需要去指明每个属性的类型,如果嫌麻烦可以用 makeAutoObservable 去替代这种写法,他是 makeObservable 的加强版,能够自动为属性加上对应的类型。
class Todo {
count = 0;
data = {
name: "",
age: -1,
};
constructor() {
makeAutoObservable(this)
}
setData(name,age) {
this.data.name = name;
this.data.age = age
}
}
8.1.2 计算属性
Mobx 的计算属性和 Vue 的 computed API 一样,在 makeObservable 中将 getter 声明为 computed,当计算属性所依赖的值发生变化时,就会重新计算该计算属性的值,让后将更新前后的值进行对比,如果更新前后的值没发生变化就会使用之前缓存的值。
- 所依赖的值具体是指什么?
官网例子
class Message {
author = {
name: "mobx",
age: 24,
};
constructor() {
makeAutoObservable(this);
autorun(() => {
console.log(this.author);
});
autorun(() => {
console.log(this.author.name);
});
}
updateAuthorName(name) {
this.author.name = name;
}
updateAuthor(author) {
this.author = author;
}
}
const message = new Message();
setTimeout(() => {
console.log("第一个setTimeout执行了~");
message.updateAuthorName("mobx1");
}, 1000);
setTimeout(() => {
console.log("第二个setTimeout执行了~");
message.updateAuthor({
name: "mobx2",
age: 25,
});
}, 3000);
// 在这个例子中我们有两个 autorun 函数,第一个函数依赖 author 对象,第二个依赖 author 对象中的 name 属性,再定义两个定时器先改变 author 对象的 name属性,再去改变整个 author 对象,我们先执行下查看下结果
//{ name: [Getter/Setter], age: [Getter/Setter] }
//mobx
//第一个setTimeout执行了~
//mobx1
//第二个setTimeout执行了~
//{ name: [Getter/Setter], age: [Getter/Setter] }
//mobx2
前两个输出就不用解释了,1s后执行第一个setTimeout的回调改变 name 的值,发现此时只打印出了 mobx1,3s后执行第二个回调,此时 **author 和 author.name **都打印出来了,这是因为第一个 autorun 函数依赖的是 author 这一个可观察对象,只有当这个可观察对象本身发生改变之后 (this.author = newAuthor )才会调用这个 autorun 函数。
2. 更新前后的值采用什么方式进行对比?
更新前后的值对比要分两种情况,如果这个值是一个原始数据类型就直接调用 === 进行比较就行,如果是引用数据类型,那么默认请况下会比较他们的引用。
8.2 什么是redux?
Redux,最为核心的概念就是 action 、reducer、store 以及 state
- action
- reducer:指明如何更新 state
- Store:把 action、Reducer 联系到一起的对象,负责维持、获取和更新state
8.3 mobx VS redux 区别 (重) >
- 函数式和面向对象
Redux更多的是遵循函数式编程(Functional Programming, FP)思想,而Mobx则更多从面向对象角度考虑问题。
Redux提倡编写函数式代码,纯函数,接受输入,然后输出结果,除此之外不会有任何影响,也包括不会影响接收的参数;对于相同的输入总是输出相同的结果。
Mobx设计更多偏向于面向对象编程(OOP)和响应式编程(Reactive Programming),通常将状态包装成可观察对象,于是我们就可以使用可观察对象的所有能力,一旦状态对象变更,就能自动获得更新。
2. 单一Store 和多个Store
在Redux应用中,我们总是将所有共享的应用数据集中在一个大的store中,
而Mobx则通常按模块将应用状态划分,在多个独立的store中管理。
3. JS对象和可观察对象
Redux默认以JavaScript原生对象形式存储数据,而Mobx使用可观察对象:
Redux需要手动追踪所有状态对象的变更;
Mobx中可以监听可观察对象,当其变更时将自动触发监听;
4. 不可变和可变
Redux状态对象通常是不可变的(Immutable),**状态是只读的,**我们不能直接操作状态对象,而总是在原来状态对象基础上返回一个新的状态对象,这样就能很方便的返回应用上一状态;
而Mobx中,**状态是可变的,**可以直接使用新值更新状态对象
9 JavaScrpt
9.1 介绍防抖、节流原理,区别以及应用,并用js实现
9.1.1 防抖:
原理:在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时,以最后一次执行事件为准。
适用场景:
按钮提交场景:防止多次提交按钮,只执行最后提交的一次。
搜索框联想场景:防止联想发送请求,只发送最后一次输入
function myDebounce(fn,wait){
let timer = null
return function(){
// 如果此时存在定时器的话,则取消之前的定时器重新计时
if(timer){
clearTimeout(timer)
timer = null
}
let context = this
let args = arguments
// 设置定时器,使事件间隔指定事件后执行
timer = setTimeout(()=>{
fn.apply(context,args)
},wait)
}
}9.1.2 节流:
原理:规定在一个单位事件内,只能触发一次函数。如果这个单位时间内触发多次函数,只有一次生效。
适用场景:
拖拽场景:固定时间内只执行一次,防止超高频次触发位置变动
缩放场景:监控浏览器的resize
- 使用时间戳实现
- 使用时间戳,当触发事件的时候,我们取出当前的时间戳,然后减去之前的时间戳(最一开始值设为 0 ),如果大于设置的时间周期,就执行函数,然后更新时间戳为当前的时间戳,如果小于,就不执行。
// 使用时间戳实现。
function myThrottle(fn,delay){
let curTime = Date.now()
return function(){
let context = this
let args = arguments
let nowTime = Date.now()
// 如果两次时间间隔超过了指定时间,则执行函数
if(nowTime - curTime >= delay){
curTime = Date.now()
return fn.apply(fn,args)
}
}
}- 使用定时器实现
- 当触发事件的时候,我们设置一个定时器,再触发事件的时候,如果定时器存在,就不执行,直到定时器执行,然后执行函数,清空定时器,这样就可以设置下个定时器。
function myThrottle(fn,delay){
let timer = null
return function(){
let context = this
let args = arguments
if(!timer){
timer = setTimeout(()=>{
fn.apply(context,args)
timer = null
},delay)
}
}
}9.1.3 区别:节流不管事件触发多频繁,保证在一定时间内一定会执行一次函数。防抖是只在最后一次事件触发后才会执行一次函数
9.2 闭包
9.2.1 什么是闭包?
函数执行后返回结果是一个内部函数,并被外部变量引用,如果内部函数持有被执行函数作用域的变量,即形成了闭包。
- 闭包三步:1.外层函数嵌套内层函数。2.内层函数使用外层函数的局部变量。3.把内层函数作为外层函数的返回值,经过这样的三步就可以形成一个闭包
- 闭包是在一个函数 A 内部有一个函数 B,通过函数 B 记录访问函数 A 内的变量。因为作用域的关系,函数A外部无法直接访问内部数据,而通过闭包这种方法可以让我们可以间接访问函数内部的私有变量,利用这一特性我们可以用来封装私有变量,实现数据寄存等
- 闭包就是指有权访问另一个函数作用域中的变量的函数
简单理解:闭包就是能够读取其他函数内部变量的函数。在JS中,只有函数内部的子函数才能读取局部变量,因此可以把闭包简单理解成“定义在一个函数内部的函数”
9.2.2 闭包原理
函数执行分成两个阶段(预编译阶段和执行阶段)。
- 在预编译阶段,如果发现内部函数使用了外部函数的变量,则会在内存中创建一个“闭包”对象并保存对应变量值,如果已存在“闭包”,则只需要增加对应属性值即可。
- 执行完后,函数执行上下文会被销毁,函数对“闭包”对象的引用也会被销毁,但其内部函数还持用该“闭包”的引用,所以内部函数可以继续使用“外部函数”中的变量
利用了函数作用域链的特性,一个函数内部定义的函数会将包含外部函数的活动对象添加到它的作用域链中,函数执行完毕,其执行作用域链销毁,但因内部函数的作用域链仍然在引用这个活动对象,所以其活动对象不会被销毁,直到内部函数被烧毁后才被销毁。
9.2.3 应用场景
1、 防抖
function myDebounce(fn,wait){
let timer = null
return function(){
if(timer){
clearTimeout(timer)
timer = null
}
let context = this
let args = arguments
timer = setTimeout(()=>{
fn.apply(context,args)
},wait)
}
}2、节流
function myThrottle(fn,delay){
let timer = null
return function(){
let context = this
let args = arguments
if(!timer){
timer = setTimeout(()=>{
fn.apply(context,args)
timer = null
},delay)
}
}
}9.3 重绘和重排
重绘不一定导致重排,但重排一定会导致重绘
9.3.1 重绘
当一个元素的外观发生改变,但没有改变布局,重新把元素外观绘制出来的过程,叫做重绘。
9.3.2 重排(回流)
当DOM的变化影响了元素的几何信息(元素的的位置和尺寸大小),浏览器需要重新计算元素的几何属性,将其安放在界面中的正确位置,这个过程叫做重排。
重排也叫回流,简单的说就是重新生成布局,重新排列元素。
下面情况会发生重排:
- 页面初始渲染,这是开销最大的一次重排
- 添加/删除可见的DOM元素
- 改变元素位置
- 改变元素尺寸,比如边距、填充、边框、宽度和高度等
- 改变元素内容,比如文字数量,图片大小等
- 改变元素字体大小
- 改变浏览器窗口尺寸,比如resize事件发生时
- 激活CSS伪类(例如::hover)
- 设置 style 属性的值,因为通过设置style属性改变结点样式的话,每一次设置都会触发一次reflow
- 查询某些属性或调用某些计算方法:offsetWidth、offsetHeight等,除此之外,当我们调用 getComputedStyle方法,或者IE里的 currentStyle 时,也会触发重排,原理是一样的,都为求一个“即时性”和“准确性”。

9.3.3 如何减少重排?
1、样式集中改变,减少使用style直接
2、将dom离线,使用display:none
一旦我们给元素设置 display:none 时(一次重排重绘),元素便不会再存在在渲染树中,相当于将其从页面上“拿掉”,我们之后的操作将不会触发重排和重绘,添加足够多的变更后,通过 display属性显示(另一次重排重绘)。通过这种方式即使大量变更也只触发两次重排。另外,visibility : hidden 的元素只对重绘有影响,不影响重排。
9.4 原型、原型链(重)>
9.4.1 原型
prototype
每一个函数都拥有一个prototype属性,指向一个对象,而这个对象就是调用该构造函数而创建的实例的原型
proto
每一个JavaScript对象(除了 null )都具有的一个属性,叫__proto__,这个属性会指向该对象的原型。
function Person() {
}
var person = new Person();
console.log(person.__proto__ === Person.prototype); // trueconstructor
每个原型都有一个 constructor 属性指向关联的构造函数。
function Person() {
}
console.log(Person === Person.prototype.constructor); // true实例对象与原型对象
当读取实例的属性时,如果找不到,就会查找与对象关联的原型中的属性,如果还查不到,就去找原型的原型,一直找到最顶层为止。
function Person() {
}
Person.prototype.name = 'Kevin';
var person = new Person();
person.name = 'Daisy';
console.log(person.name) // Daisy
delete person.name;
console.log(person.name) // Kevin
9.4.2 原型链
实例对象.__proto__往上查找的一层层关系链就是原型链
9.5 继承(重)>
9.5.1 原型链继承
// 原型链继承
function Parent(){
this.name = 'Kevin'
}
Parent.prototype.getName = function(){
console.log(this.name)
}
function Child(){}
// 父构造函数的实例 等于 子构造函数的原型
Child.ptototype = new Parent()
// 创建子构造函数实例
const child1 = new Child()
console.log(child1.getName()) // kevin缺点1: 引用类型的属性被所有实例共享
function Parent(){
this.name = ['kevin','daisy']
}
function Child(){}
Child.prototype = new Parent()
const child1 = new Child()
child1.name.push('yayu')
console.log(child1.name) // ["kevin", "daisy", "yayu"]
const child2 = new Child()
console.log(child2.name) // ["kevin", "daisy", "yayu"]
缺点2: 在创建子构造函数Child的实例的时候,不能向父构造函数传参
9.5.2 借用构造函数继承(经典继承)
// 借用构造函数继承
function Parent(age){
this.name = ['kevin', 'daisy']
this.age = age
}
function Child(age){
// this 指向 Child() 的实例
Parent.call(this,age)
}
const child1 = new Child(1)
child1.name.push('yayu')
console.log(child1.name) // ["kevin", "daisy", "yayu"]
console.log(child1.age) // 1
const child2 = new Child(2)
console.log(child2.name) // ["kevin", "daisy"]
console.log(child2.age) // 2优点1: 避免了引用类型属性被所有实例共享
优点2: 可以在Child中向Parent传参
缺点1: 方法都在构造函数中定义,每次创建实例都会创建一遍方法。
9.5.3 组合继承
// 组合继承
function Parent(name){
this.name = name
this.colors = ['red', 'blue', 'green']
}
Parent.prototype.getName = function(){
console.lot(this.name)
}
function Child(name,age){
this.age = age
Parent.call(this,name)
}
Child.prototype = new Parent()
Child.prototype.constructor = Child
const child1 = new Child('kevin','18')
child1.colors.push('black')
console.log(child1.name) // kevin
console.log(child1.age) // 18
console.log(child1.colors) // ["red", "blue", "green", "black"]
const child2 = new Child('daisy', '20')
console.log(child2.name); // daisy
console.log(child2.age); // 20
console.log(child2.colors); // ["red", "blue", "green"]优点:融合原型链继承和构造函数继承的优点
9.5.4 原型式继承(Object.create())
function createObj(o) {
function F(){}
F.prototype = o;
return new F();
}就是 ES5 Object.create 的模拟实现,将传入的对象作为创建的对象的原型。
缺点:和原型链继承一样,引用类型的属性会被所有实例共享
9.5.5 寄生式继承
function createObj (o) {
var clone = Object.create(o);
clone.sayName = function () {
console.log('hi');
}
return clone;
}创建一个仅用于封装继承过程的函数,该函数在内部以某种形式来做增强对象,最后返回对象。
缺点:跟借用构造函数模式一样,每次创建对象都会创建一遍方法。
9.5.6 寄生组合式继承
function Parent (name) {
this.name = name;
this.colors = ['red', 'blue', 'green'];
}
Parent.prototype.getName = function () {
console.log(this.name)
}
function Child (name, age) {
Parent.call(this, name);
this.age = age;
}
Child.prototype = new Parent();
var child1 = new Child('kevin', '18');
console.log(child1)组合继承最大的缺点是会调用两次父构造函数。
一次是设置子类型实例的原型的时候:
Child.prototype = new Parent();一次在创建子类型实例的时候:
var child1 = new Child('kevin', '18');回想下 new 的模拟实现,其实在这句中,我们会执行:
Parent.call(this, name);在这里,我们又会调用了一次 Parent 构造函数。
所以,在这个例子中,如果我们打印 child1 对象,我们会发现 Child.prototype 和 child1 都有一个属性为colors,属性值为[‘red’, ‘blue’, ‘green’]。
那么我们该如何精益求精,避免这一次重复调用呢?
如果我们不使用 Child.prototype = new Parent() ,而是间接的让 Child.prototype 访问到 Parent.prototype 呢?
function Parent (name) {
this.name = name;
this.colors = ['red', 'blue', 'green'];
}
Parent.prototype.getName = function () {
console.log(this.name)
}
function Child (name, age) {
Parent.call(this, name);
this.age = age;
}
// 关键的三步
var F = function () {};
F.prototype = Parent.prototype;
Child.prototype = new F();
var child1 = new Child('kevin', '18');
console.log(child1);封装一下这个继承方法:
// 传入一个对象
function object(o) {
function F() {}
// F的原型等于这个传入的对象
F.prototype = o;
// 最后返回这个F函数
return new F();
}
function prototype(child, parent) {
var prototype = object(parent.prototype);
prototype.constructor = child;
child.prototype = prototype;
}
// 当我们使用的时候:
prototype(Child, Parent);9.6 new操作符做了什么? 模拟实现new操作符
9.6.1 new操作符做了什么?
1、创建一个空对象
2、将这个空对象的原型指向构造函数
3、改变构造函数this指向空对象
4、根据返回值的类型进行判断,如果是对象,就返回创建的这个对象,如果不是,该返回什么就返回什么
9.6.2 new操作符 简单实现
function mynew(Func, ...args) {
// 1.创建一个新对象
const obj = {}
// 2.新对象原型指向构造函数原型对象
obj.__proto__ = Func.prototype
// 3.将构建函数的this指向新对象
let result = Func.apply(obj, args)
// 4.根据返回值判断
return result instanceof Object ? result : obj
}// 模拟实现new操作符
function objectFactory() {
// 用new Object() 的方式新建了一个对象 obj
var obj = new Object(),
// 取出第一个参数,就是我们要传入的构造函数。此外因为 shift 会修改原数组,所以 arguments 会被去除第一个参数
Constructor = [].shift.call(arguments);
// 将 obj 的原型指向构造函数,这样 obj 就可以访问到构造函数原型中的属性
obj.__proto__ = Constructor.prototype;
// 使用 apply,改变构造函数 this 的指向到新建的对象,这样 obj 就可以访问到构造函数中的属性
var ret = Constructor.apply(obj, arguments);
// 判断返回的值是不是一个对象,如果是一个对象,我们就返回这个对象,如果没有,我们该返回什么就返回什么。
return typeof ret === 'object' ? ret : obj;
};9.7 深拷贝和浅拷贝的区别是什么?如何实现深拷贝和浅拷贝。
9.7.1 区别
- 浅拷贝指的是将复杂数据类型在栈中保存的地址复制一份,所指向的数据是同一份。修改原值会影响新值。
- 深拷贝是指将复杂数据类型完整的复制一份,拷贝对象的属性并重新创建一个对象,不会影响原始值。
9.7.2 实现
深拷贝实现
1、lodash(_cloneDeep())
2、递归 (重) >
// 手写实现深拷贝
function myDeepClone(obj){
// 通过传入的obj数据类型 选择创建一个空对象或者空数组
let objClone = Array.isArray(obj) ? [] : {}
// 如果obj是对象类型
if(obj && typeof obj === 'object'){
// for in 循环obj
for(key in obj){
// 判断是否为自身属性 obj.hasOwnProperty()
if(obj.hasOwnProperty(key)){
// 判断obj子元素是否为对象,如果是,递归复制
if(obj[key] && typeof obj[key] === 'object'){
objClone[key] = myDeepClone(obj[key])
}else{
// 如果不是对象 简单复制
objClone[key] = obj[key]
}
}
}
}
// 最后返回这个对象
return objClone
}3、JSON.parse(JSON.stringify())
缺点:
- 不能拷贝函数
- undefined、任意的函数以及 symbol 值,在序列化过程中会被忽略
对象深拷贝实现
1、Object.assign({},originObject)
let a = {
age:1,
person:{
name:'xinxin'
}
}
// 第一层不影响
let b = Object.assign({},a);
console.log(b.age);// 1
b.age = 2;
console.log(a.age) // 1
// 第二层互相影响
b.person.name = 'xin';
console.log(a.person.name) // 'xin'2、解构{ …originObject }
let a = {
age:1,
person:{
name:'xinxin'
}
}
// 用法
let b = { ...a }
// 效果同第一种一样,第一层不互相影响,第二层开始相互影响3、lodash(_.cloneDeep())
拷贝规则同Object.assign;
let obj2 = _.clone(obj1);
9.8 typeof 和 instanceof 的原理以及区别是什么? 并手动实现instanceof
9.8.1 typeof
typeof操作符 返回一个字符串
typeof 1 // 'number'
typeof '1' // 'string'
typeof undefined // 'undefined'
typeof true // 'boolean'
typeof Symbol() // 'symbol'
typeof null // 'object'
typeof [] // 'object'
typeof {} // 'object'
typeof console // 'object'
typeof console.log // 'function'typeof只能判别基础类型数据,除了function外,所有引用类型的数据都会被判别为object,并且,typeof null 会被认为object ,js的一个远古bug
9.8.2 instanceof
instanceof 运算符用于检测构造函数的 prototype 属性是否出现在某个实例对象的原型链上
https://segmentfault.com/a/1190000018874474
A instanceof B
原理:判断B的原型(B.prototype)是不是在左边A的原型链上
function instance_of (left, right){
// 右边的原型
const rightPrototype = right.prototype
while(true){
if(left === null){
return false
}
if(left === rightPrototype){
return true
}
// 重新赋值
left = left.__proto__
}
}
// 方法二
function myInstanceof (left, right){
// 获取左边对象的原型
let proto =Object.getPrototype(left)
// 获取右边构造函数的prototype对象
let rightPrototype = right.prototype
// 判断构造函数的prototype对象是不是在左边对象的原型链上
whilt(true){
if(proto===null){
return false
}
if(proto === rightPrototype){
return true
}
// 如果没有找到,就继续从原型上向上找,Object.getPrototype()方法用来获取指定对象的原型
proto = Object.getPrototype(proto)
}
}9.9 == 和 === 的区别
== 先进行类型转换,再确定操作数是否相等
=== 对比较的两个值 进行类型和值得比较。校验相对来说更严谨
9.10 js延迟加载脚本的方式有哪些?(async和defer的区别)
1)defer属性:异步加载 JS 文件,全部 JS 文件加载完毕后,且 HTML 文档解析完毕之后,按顺序执行 JS 文件,这样不会使页面渲染造成堵塞;
2)async属性:用于异步下载脚本文件,下载完毕立即解释执行代码,不会阻止页面其他动作。
注意: aysnc 和 defer 都是针对于外部脚本,但是async并不能保证按照script标签出现的顺序执行,而且实际上,defer也不能保证,所以最好只有一个defer
3)Js最后加载,把Js脚本放在文档地步,使JS脚本尽可能的最后加载执行;
4)使用setTimeout定时器延迟加载js脚本文件。
9.11 for…in 和 for…of的区别
for…of是ES6新增的遍历方式,
区别:
for…of是遍历的对象的键值(value) for…in遍历的是对象的键(key)
for…in会遍历对象的整个原型链,而for…of只遍历当前对象,不遍历原型链, 所以不推荐使用for…in遍历对象
对于数组的遍历,for…in会返回数组中所有可枚举的属性(包括原型链上可枚举的属性),for…of只返回数组的下表
总结:for…in是为遍历对象而生,不适用于遍历数组,for…of只返回数组下表对应的属性值
9.12 null和undefined的区别
undefined的含义是未定义,通常用于基本数据类型的初始值
null的含义是空对象,通常用于object的初始值
null 和 undefined 比较,相等操作符(==)为true,全等为false
let result1 = (null == undefined ); // true
let result2 = (null === undefined); // false9.13 箭头函数和普通函数的区别
- 箭头函数没有自己的this,如果在箭头函数中使用this,会指向上层作用域中this的指向
- 箭头函数不能当作构造函数
- 箭头函数没有自己的原型对象
- 箭头函数的写法更简洁
- 箭头函数没有自己的arguments
9.14 常用的数组方法
- pop() 删除最后一项
- push() 尾部添加
- shift() 头部删除
- unshift() 头部添加
- map() 循环数组,具有返回值, 不会对原数组造成影响
- filter() 筛选数组,具有返回值, 不会对原数组造成影响
- forEach 循环数组,对原数组会造成影响
- splice 切割数组
splice() ★★★★★ 对原数组进行操作
删除 : 接收两个参数 splice(开始元素的索引,要删除元素的数量) 返回删除的元素
let arr = [1,2,3]
arr.splice(0,1)
console.log(arr.splice(0,1)) // 1 因为索引为0的元素为1
console.log(arr) // [2,3] 原数组第0个元素被删除**插入: 接收三个参数 splice(开始元素的索引,要删除元素的数量,要插入的元素) **
let arr = [1,2,3]
let handle = arr.splice(0, 0, '插入的字符串a' , '插入的字符串b' ) // 从索引为0的地方开始插入元素
console.log(handle) // [] 返回一个空数组
console.log(arr) // ['插入的字符串a','插入的字符串b’,1,2,3] 替换: 接收三个参数 splice(开始元素的索引,要删除元素的熟练, 要插入的元素) 返回被替换掉的元素
let arr = [1,2,3]
let handle = arr.splice(1, 1, '插入的字符串a' ) // 从索引为1的地方开始 删除1 个元素 然后添加'插入的字符串a'
console.log(handle) // [2] 返回一个空数组
console.log(arr) // [1,'插入的字符串a',3] 9.15 事件代理(事件委托)
事件代理,俗地来讲,就是把一个元素响应事件(click、keydown…)的函数委托到另一个元素
事件流的都会经过三个阶段:** 捕获阶段 -> 目标阶段 -> 冒泡阶段**,而事件委托就是在冒泡阶段完成
事件委托,会把一个或者一组元素的事件委托到它的父层或者更外层元素上,真正绑定事件的是外层元素,而不是目标元素
9.16 call、bind、aplly的区别? 如何实现?
9.16.1 作用
call、bind、apply都是用来改变this指向的。
9.16.2 区别
- call、bind方法的第二个参数,是枚举形式的
- apply方法第二个参数是一个数组
- call、apply方法改变this指向后会原函数立即执行,bind方法改变this指向后原函数不会立即调用,而是返回一个永久改变this指向的函数
9.16.3 实现
实现call方法
// call方法的实现
Function.prototype.MyCall = function(context){
// 判断调用对象
if(typeof this !== "function"){
throw new TypeError("Error")
}
// 获取参数
let args = [...arguments].slice(1)
let result = null
// 判断context是否传入,如果未传入则设置为window
context = context || window
//将调用函数设为对象的方法
context.fn = this
// 调用函数
result = context.fn(...args)
// 将属性删除
delete context.fn
return result
}实现bind方法
// bind函数的实现
Function.prototype.MyBin = function(context){
// 判断调用对象
if(typeof this !== "function"){
throw new TypeError("Error")console.log("type error")
}
// 获取参数
let args = [...arguments].slice(1)
let fn = this
return function Fn(){
// 根据调用方式 传入不同绑定值
return fn.apply(
// 对三目运算符两种情况对解释
// 1、当作为构造函数时,this指向实例(这里对this是bind返回对新方法里执行时的this,和上面的this不是一个。)Fn为绑定函数,此时结果为true,this指向实例
// 2、当作为普通函数时,this指向window,Fn为绑定函数,此时结果为false 当结果为false的时候,this指向绑定的context
this instanceof Fn ? this : context
args.concat(...arguments)
)
}
}实现aplly方法
// apply函数的实现
Function.prototype.MyAplly = function(context){
if(typeof this !== "function"){
throw new TypeError("Error")
}
let result = null
context = context || window
// 将调用函数设置为对象的方法
context.fn = this
if(arguments[1]){
result = context.fn(arguments[1])
}else{
result = context.fn()
}
delete context.fn
return result
}9.17 输入url发生了什么?(重) >
URL解析->->DNS查询->根据IP建立TCP链接(三次握手)->发送HTTP请求->服务器处理请求,浏览器接收HTTP响应->浏览器渲染构建DOM树->关闭TCP链接(四次挥手)
9.17.1 URL解析
首先判断你输入的是一个合法的URL 还是一个待搜索的关键词,并且根据你输入的内容进行对应操作
URL的解析第过程中的第一步,一个url的结构解析如下:
9.17.2 DNS查询
主要是为了根据域名获取对应的服务器IP地址
9.17.3 TCP链接(三次握手)
tcp是一种面向有连接的传输层协议
在确定目标服务器服务器的IP地址后,则经历三次握手建立TCP连接,
第一次握手: 建立连接时,客户端发送 syn 包(syn=j)到服务器,并进入等待服务器确认的状态
第二次握手: 服务器收到 syn 包,必须确认客户端的 syn(ack=j+1),同时自己根据 syn 生成一个 ACK 包,此时服务器进入等待状态
第三次握手: 客户端收到服务器的 ACK 包,向服务器发送确认,此包发送完毕,客户端和服务器进入 ESTABLISHED( TCP 连接成功)状态,完成三次握手。

9.17.4 向服务器发送HTTP请求
9.17.5 服务器处理请求,浏览器接收HTTP响应
9.17.6 页面渲染,构建DOM树
关于页面的渲染过程如下:
- 解析HTML,构建 DOM 树
- 解析 CSS ,生成 CSS 规则树
- 合并 DOM 树和 CSS 规则,生成 render 树
- 布局 render 树( Layout / reflow ),负责各元素尺寸、位置的计算
- 绘制 render 树( paint ),绘制页面像素信息
- 浏览器会将各层的信息发送给 GPU,GPU 会将各层合成( composite ),显示在屏幕上

9.17.7 关闭TCP链接(四次挥手)
- 第一次握手是浏览器发完数据,然后发送FIN请求断开连接。
- 第二次握手是服务器向客户端发送ACK,表示同意。
- 第三次握手是服务器可能还有数据向浏览器发送,所以向浏览器发送 ACK 同时也发送 FIN 请求,是第三次握手。
- 第四次握手是浏览器接受返回的 ACK,表示数据传输完成。
9.18 说说为什么TCP需要三次握手和四次挥手?
9.18.1 三次握手
三次握手(Three-way Handshake)其实就是指建立一个TCP连接时,需要客户端和服务器总共发送3个包
- 第一次握手:客户端给服务端发一个 SYN 报文,并指明客户端的初始化序列号 ISN(c),此时客户端处于 SYN_SENT 状态
- 第二次握手:服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,为了确认客户端的 SYN,将客户端的 ISN+1作为ACK的值,此时服务器处于 SYN_RCVD 的状态
- 第三次握手:客户端收到 SYN 报文之后,会发送一个 ACK 报文,值为服务器的ISN+1。此时客户端处于 ESTABLISHED 状态。服务器收到 ACK 报文之后,也处于 ESTABLISHED 状态,此时,双方已建立起了连接

9.18.2 三次握手的原因
如果是两次握手,发送端可以确定自己发送的信息能对方能收到,也能确定对方发的包自己能收到,但接收端只能确定对方发的包自己能收到 无法确定自己发的包对方能收到
并且两次握手的话, 客户端有可能因为网络阻塞等原因会发送多个请求报文,延时到达的请求又会与服务器建立连接,浪费掉许多服务器的资源
9.18.3 四次挥手
tcp终止一个连接,需要经过四次挥手
过程如下:
- 第一次挥手:客户端发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于 FIN_WAIT1 状态,停止发送数据,等待服务端的确认
- 第二次挥手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 +1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT状态
- 第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态
- 第四次挥手:客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 +1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态,服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态

9.18.4 四次挥手的原因
服务端在收到客户端断开连接Fin报文后,并不会立即关闭连接,而是先发送一个ACK包先告诉客户端收到关闭连接的请求,只有当服务器的所有报文发送完毕之后,才发送FIN报文断开连接,因此需要四次挥手
10 网络协议部分
10.1 GET和POST的区别
GET方法请求一个指定资源的表示形式,使用GET的请求应该只被用于获取数据
POST方法用于将实体提交到指定的资源,也就是发送数据
区别
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET请求在URL中传送的参数是有长度限制的,而POST没有
- GET不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body中
- GET是用于获取数据,所以是幂等,POST是用来发送数据,所以不是幂等
幂等性简单理解就是同一个请求,发送一次和发送 N 次效果是一样的
10.2 HTTP和HTTPS的区别
http 是明文传输,没有安全保证,对服务端和客户端来说都无法验明双方身份
https 使用了ssl加密方式,服务端和服务端可以验明双方的身份,安全有了一定的保障。但是需要解密和加密,对性能会造成一定的影响。
http端口号是80 ,https端口号是443。
10.4 跨域是什么? 如何解决?
10.5 跨域如何携带cookie?
11 前端路由的实现
11.1 hash路由
实现原理
通过监听hashchange事件来监听页面的hash变化,通过解析hash值来切换页面
/**
* 解析 hash
* @param hash
* @returns
*/
function parseHash(hash) {
// 去除 # 号
hash = hash.replace(/^#/, "");
// 简单解析示例
const parsed = hash.split("?");
// 返回 hash 的 path 和 query
return {
pathname: parsed[0],
search: parsed[1],
};
}
/**
* 监听 hash 变化
* @returns
*/
function onHashChange() {
// 解析 hash
const { pathname, search } = parseHash(location.hash);
// 切换页面内容
switch (pathname) {
case "/home":
document.body.innerHTML = `Hello ${search}`;
return;
default:
return;
}
}
window.addEventListener("hashchange", onHashChange);优点
1、兼容性最佳
2、无需服务端配置
缺点
1、服务端无法获取hash部分内容
2、可能和锚点功能冲突
3、SEO不友好
11.2 History路由
实现原理
History路由主要依赖History API的两个方法(history.pushState, history.replaceState)一个事件(popstate),其中两个方法用于操作浏览器的历史记录,事件用于监听历史记录的切换
方法
- history.pushState:将给定的 Data 添加到当前标签页的历史记录栈中。
- history.replaceState:将给定的 Data 更新到历史记录栈中最新的一条记录中。
事件
- popstate:监听历史记录的变化。
/**
* 监听 history 变化
* @returns
*/
function onHistoryChange() {
// 解析 location
const { pathname, search } = location;
// 根据页面不同执行不同内容
switch (pathname) {
case "/home":
document.body.innerHTML = `Hello ${search.replace(/^\?/, "")}`;
return;
default:
document.body.innerHTML = `Hello World`;
return;
}
}
/**
* 页面跳转
* @returns
*/
function pushState(target) {
history.pushState(null, "", target);
onHistoryChange();
}
// 3 秒后路由跳转
setTimeout(() => {
pushState("/home?name=HZFEStudio");
}, 3000);
// 6 秒后返回
setTimeout(() => {
history.back();
}, 6000);
window.addEventListener("popstate", onHistoryChange);优点
1、服务端可以获取完整的链接和参数
2、前端监控友好
3、SEO相对Hash路由友好
缺点
1、兼容性稍弱
2、需要服务端额外配置(各path均指向同一个HTML)
12 谈谈微前端
12.1 关键点
**微前端是一种架构理念,它将较大的前端应用拆分为若干个可以独立交付的前端应用。**这样的好处是每个应用大小及复杂度相对可控。在合理拆分应用的前提下,微前端能降低应用之间的耦合度,提升每个团队的自治能力。
12.2 微前端部分核心能力
12.2.1 路由管理
一般我们使用 Hash 或者 History 模式来对路由进行监听,如 hashchange 或 popstate 事件。
目前常见的微前端解决方案主要是路由驱动的。在微前端的基座,进行子应用的路由注册,如 { path: ‘/microA/*’ } ,基座根据路由匹配情况,按需挂载子应用。具体路由跳转规则由子应用接管响应。
12.2.2 隔离机制
支持样式隔离和 JS 沙箱机制,以保证应用之间的样式或全局变量、事件等互不干扰。在应用卸载时,应当对子应用中产生的事件、全局变量、样式表等进行卸载。
对于新的项目,做好样式隔离的方式包括采用 CSS Module、CSS in JS 或规范使用命名空间等。对于已有项目的 CSS 隔离,可以在打包阶段利用工具(如 postcss)自动对样式添加前缀。
实现 JS 沙箱机制可以借助 Proxy 和 with 的能力,分别做对 Window 对象的访问进行拦截和修改子应用作用域的操作。不支持 Proxy 的宿主环境,可以采用快照的思路:对进入子应用前的 Window 对象进行快照,用于后续卸载子应用时还原 Window 对象;在卸载子应用时对 Window 对象进行快照,用于后续再次加载子应用时还原 Window 对象。
12.2.3 消息通信
合理划分应用,可以避免频繁的跨应用通信。同时应当避免子应用之间直接通信。
常见的消息通信机制可以通过原生 CustomEvent 类实现,子应用通过 dispatchEvent 和 addEventListener 来对自定义事件进行下发和监听。除此之外,借助 props 通过主应用向子应用传参,达到通信目的也是常见方法。
12.2.4 依赖管理
常见的微前端框架中,基座应用统一对子应用的状态进行管理。根据路由和子应用状态,按需触发生命周期函数,做请求加载、渲染、卸载等动作。而多个子应用间可能存在一些公共库的依赖。
为减少这类资源的重复加载,通常可以借助 webpack5 的 Module Federation 在构建时进行公共依赖的配置,实现运行时依赖共享的能力。除了使用打包工具的能力,也可以从代码层面通过实现类 external 功能对公共依赖进行管理。
13 React框架
13.1 React事件机制原理
相关问题
- React 合成事件与原生 DOM 事件的区别
- React 如何注册和触发事件
- React 事件如何解决浏览器兼容问题
关键点
React 的事件处理机制可以分为两个阶段:初始化渲染时在 root 节点上注册原生事件;原生事件触发时模拟捕获、目标和冒泡阶段派发合成事件。通过这种机制,冒泡的原生事件类型最多在 root 节点上注册一次,节省内存开销。且 React 为不同类型的事件定义了不同的处理优先级,从而让用户代码及时响应高优先级的用户交互,提升用户体验。
React 的事件机制中依赖合成事件这个核心概念。合成事件在符合 W3C 规范定义的前提下,抹平浏览器之间的差异化表现。并且简化事件逻辑,对关联事件进行合成。如每当表单类型组件的值发生改变时,都会触发 onChange 事件,而 onChange 事件由 change、click、input、keydown、keyup 等原生事件组成。
13.1.1 原生事件和合成事件
JavaScript 通过事件可以和 DOM 进行交互。
原生事件
在事件发生时,相关信息会存储在** Event 的实例对象**中,对象包含 currentTarget、detail、target、**preventDefault()、stopPropagation() **等属性和方法。DOM 节点可以通过 addEventListener 和 removeEventListener 来添加或移除事件监听函数。
// Event 属性
boolean bubbles
boolean cancelable
DOMEventTarget currentTarget
boolean defaultPrevented
number eventPhase
boolean isTrusted
void preventDefault()
void stopPropagation()
void stopImmediatePropagation()
DOMEventTarget target
number timeStamp
string type合成事件
React 的事件机制中,在遵循规范的前提下,引入新的事件类型:合成事件(SyntheticEvent)。基于合成事件实现了浏览器中常见的用户事件,并对事件进行规范化处理,使它们在不同浏览器中具有一致的属性。
在事件发生时,相关信息会存储在 合成事件(SyntheticEvent) 的实例对象中,对象包含原生事件对象类似的属性。
// SyntheticEvent 属性
boolean bubbles
boolean cancelable
DOMEventTarget currentTarget
boolean defaultPrevented
number eventPhase
boolean isTrusted
DOMEvent nativeEvent
void preventDefault()
boolean isDefaultPrevented()
void stopPropagation()
boolean isPropagationStopped()
void persist()
DOMEventTarget target
number timeStamp
string type但是合成事件与原生事件不是一一映射的关系。比如 onMouseEnter 合成事件映射原生 mouseout、mouseover 事件。React 通过 registrationNameDependencies 来记录合成事件和原生事件的映射关系:
/**
* Mapping from registration name to event name
*/
export const registrationNameDependencies = {
onClick: ["click"],
onMouseEnter: ["mouseout", "mouseover"],
onChange: [
"change",
"click",
"focusin",
"focusout",
"input",
"keydown",
"keyup",
"selectionchange",
],
// ...
};13.1.2 React事件机制
React事件注册

使用 ReactDOM.createRoot 创建 Root 时,React 会调用 **listenToAllSupportedEvents **方法对所有支持的原生事件进行监听:
function listenToAllSupportedEvents(rootContainerElement) {
// ...
// allNativeEvents是所有的native事件
// 遍历所有原生事件
// 除了不需要在冒泡阶段添加事件代理的原生事件,仅在捕获阶段添加事件代理
// 其余的事件都需要在捕获、冒泡阶段添加代理事件
allNativeEvents.forEach(function (domEventName) {
// nonDelegatedEvents(非委托事件)中的事件都是不能冒泡的元素,如果该事件不能冒泡,就只绑定捕获阶段,否则两个阶段都绑定
// 如果能冒泡
if (!nonDelegatedEvents.has(domEventName)) {
listenToNativeEvent(domEventName, false, rootContainerElement, null);
}
// 如果不能冒泡
listenToNativeEvent(domEventName, true, rootContainerElement, null);
});
}
- allNativeEvents 用于收集所有合成事件相关联的原生事件名。这个收集动作在事件插件初始化阶段完成;
SimpleEventPlugin.registerEvents();
EnterLeaveEventPlugin.registerEvents();
ChangeEventPlugin.registerEvents();
SelectEventPlugin.registerEvents();
BeforeInputEventPlugin.registerEvents();- 对每个原生事件调用** addTrappedEventListener 函数。该函数最终使用 addEventListener **方法,对原生事件进行捕获或冒泡阶段的事件监听注册。
function addTrappedEventListener(
targetContainer: EventTarget,
domEventName: DOMEventName,
eventSystemFlags: EventSystemFlags,
isCapturePhaseListener: boolean
) {
let listener = createEventListenerWrapperWithPriority(
targetContainer,
domEventName,
eventSystemFlags
);
// ...
if (isCapturePhaseListener) {
addEventCaptureListener(targetContainer, domEventName, listener);
} else {
addEventBubbleListener(targetContainer, domEventName, listener);
}
}基于以上流程可知,调用 ReactDOM.createRoot 方法时,就已经在 root 节点上初始化所有原生事件的监听回调函数。而不是在组件上写合成事件的监听时,才开始注册事件回调。
React事件的触发

function dispatchEventsForPlugins(
domEventName: DOMEventName,
eventSystemFlags: EventSystemFlags,
nativeEvent: AnyNativeEvent,
targetInst: null | Fiber,
targetContainer: EventTarget,
): void {
const nativeEventTarget = getEventTarget(nativeEvent);
const dispatchQueue: DispatchQueue = [];
// 事件对象的合成,收集事件到执行路径上
extractEvents(
dispatchQueue,
domEventName,
targetInst,
nativeEvent,
nativeEventTarget,
eventSystemFlags,
targetContainer,
);
// 执行收集到的组件中真正的事件
processDispatchQueue(dispatchQueue, eventSystemFlags);
}
dispatchQueue是一个数组,每一项包含了一个合成事件及其该合成事件对应的回调函数(listeners),extractEvents负责合成事件并调用相关的方法来收集事件响应链路,processDispatchQueue负责执行事件的回调函数
在注册事件阶段调用的 addTrappedEventListener 方法中,会使用 createEventListenerWrapperWithPriority 函数来创建事件回调。createEventListenerWrapperWithPriority 函数根据事件类型,划分出若干个不同优先级的 dispathEvent。事件回调最终都调用进 dispatchEvent 方法。
因此触发一个原生事件时,大致的执行流程如下:
- 原生事件触发后,进入 dispatchEvent 回调方法;
- attemptToDispatchEvent 方法根据该原生事件查找到当前原生 Dom 节点和映射的 Fiber 节点;
- 事件和 Fiber 等信息被派发给插件系统进行处理,插件系统调用各插件暴露的 extractEvents 方法;
- accumulateSinglePhaseListeners 方法向上收集 Fiber 树上监听相关事件的其他回调函数,构造合成事件并加入到派发队列 dispatchQueue 中;
- 调用 processDispatchQueue 方法,基于捕获或冒泡阶段的标识,按倒序或顺序执行 dispatchQueue 中的方法;
总结 (重) >
首先React是采用事件委托的方式绑定事件,react事件机制可以分为两个阶段。1、初始化的时候,在根结点root上注册监听所有事件(React17的事件是注册到root上而非document,这主要是为了渐进升级,避免多版本的React共存的场景中事件系统发生冲突),意思就是使用ReactDOM.createRoot创建根结点Root时,会调用listenToAllSupportedEvents()方法监听所有事件,内部实现原理是遍历所有的事件(allNativeEvents),然后调用listenToNativeEvent()方法(listenToNativeEvet方法内部调取的是addTrappedEventListener()方法,而这个方法最终是调用的addEventListener方法,完成的事件监听绑定)去完成事件监听绑定,(对于不向上冒泡的事件,直接绑定在对应事件的dom节点上);2、触发阶段,比如一个button按钮,点击事件被触发以后,会执行dispatchEvent()函数(触发器),然后执行attemptToDispatchEvent()方法获取到当前原生Dom节点以及映射的Fiber节点(这个原生事件作为prop绑定这个这个fiber节点上),然后将事件以及Fiber等信息派发给插件系统进行处理进行事件合成(调用dispatchEventsForPlugins方法对native事件进行合成),接下来就是extractEvents函数(提取事件函数)会调用accumulateSinglePhaseListeners()方法(收集事件函数)收集需要执行的监听函数,并放在dispatchQueue对象中,最后去执行相应的监听函数(在processDispatchQueue函数中执行对应的监听函数)。